The coronavirus disease 2019 (COVID-19) pandemic has had devastating consequences in low- and lower-middle-income countries (LMICs). The living standards of the most economically vulnerable individuals have further worsened with a transition toward extreme poverty. Governments and humanitarian organizations worldwide have been trying to provide social assistance to the needy.
In high-income nations, governments have used the recent income data of individuals to assess their socioeconomic status and disbursed funds accordingly. However, in low-income countries, such data is either unavailable or obsolete. Thus, it has been challenging to identify individuals who require the greatest humanitarian aid.
About the study
In the present study, researchers developed a machine-learning-based approach to estimate poverty and target the poorest Togolese population for social assistance. This approach was termed a ‘phone-based approach’ by the authors of the present study.
The Togolese government had launched the Novissi program in April 2020 to provide monetary aid to informal workers. The authors aimed to expand this program to the poorest Togolese residents, who were agricultural workers. Their phone-based approach was a two-step process.
In the first step, satellite and mobile phone data were obtained and analyzed by machine-learning algorithms. For the analysis, Togo was divided into several grid cells. Next, the algorithms estimated the relative wealth of people residing within every grid cell that represented the 2.4-km regions of the country. Subsequently, a population-weighted average of these grids was calculated for estimating the average wealth of every canton, Togo’s smallest administrative unit.
In the second step, mobile phone data provided by two Togolese mobile phone operators and obtained on an extensive survey were matched and analyzed by the machine-learning algorithms to determine the average daily consumption of every mobile phone subscriber.
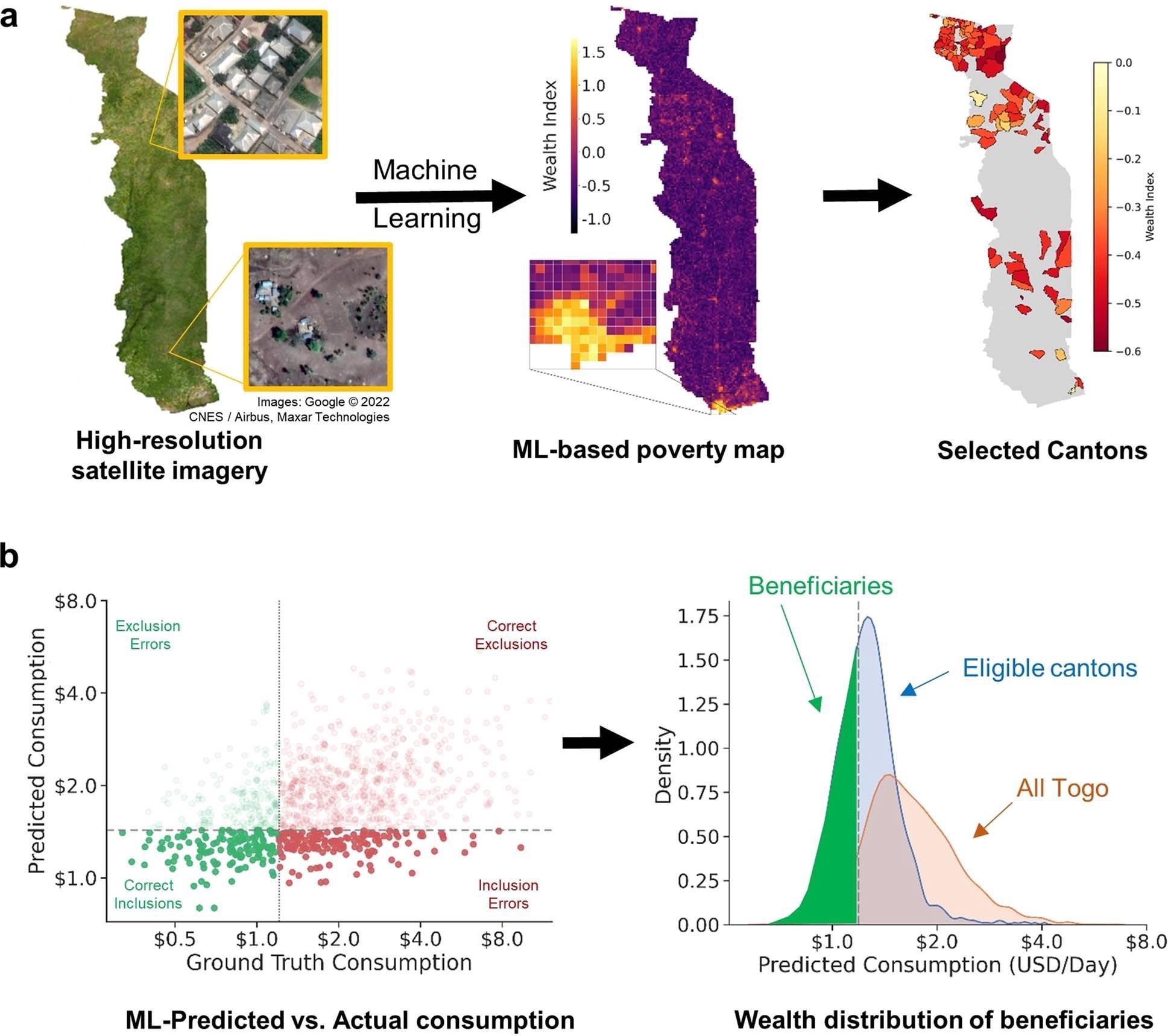 a) Regional targeting. Satellite imagery of Togo is used to construct micro-estimates of poverty (middle)16, which are overlayed with population data to produce canton-level estimates of wealth. Individuals registered in the 100 poorest cantons (right) are eligible for benefits. Inset images © 2019 Google. b) Individual targeting. A machine-learning algorithm is trained using representative survey data to predict consumption from features of phone use (Methods, ‘ Machine-learning methods’). The algorithm constructs poverty scores that are correlated with ground-truth measures of consumption (left). Subscribers who register for the program in targeted cantons with estimated consumption of less than USD $1.25/day are eligible for benefits (right). The red distribution shows the predicted wealth distribution of the entire population of Togo; the blue distribution shows the predicted wealth distribution in the 100 poorest cantons, and the green section indicates the predicted wealth distribution of Novissi beneficiaries.
a) Regional targeting. Satellite imagery of Togo is used to construct micro-estimates of poverty (middle)16, which are overlayed with population data to produce canton-level estimates of wealth. Individuals registered in the 100 poorest cantons (right) are eligible for benefits. Inset images © 2019 Google. b) Individual targeting. A machine-learning algorithm is trained using representative survey data to predict consumption from features of phone use (Methods, ‘ Machine-learning methods’). The algorithm constructs poverty scores that are correlated with ground-truth measures of consumption (left). Subscribers who register for the program in targeted cantons with estimated consumption of less than USD $1.25/day are eligible for benefits (right). The red distribution shows the predicted wealth distribution of the entire population of Togo; the blue distribution shows the predicted wealth distribution in the 100 poorest cantons, and the green section indicates the predicted wealth distribution of Novissi beneficiaries.
The phone-based targeting approach was compared to three other feasible targeting approaches, geographic targeting [selecting individuals in the poorest cantons (Togo’s admin-3 level) or poorest prefectures (Togo’s admin-2 level], occupation-based targeting (selecting informal workers), and phone expenditure-based method that used estimated poverty based on an individual’s mobile phone usage expenditure (calling and texting). In addition, the authors used ‘optimal’ targeting, that selected agricultural workers as the poorest population.
The comparative effectiveness of the targeting approaches was considered for two scenarios. The first scenario targeted the rural Togolese population and evaluated the existing policy situation faced by the Togolese government during September 2020. The data used for analysis was based on a survey conducted by the authors during the same period. The proxy means test (PMT) was used as a ground-truth estimate of true poverty.
The second scenario targeted nationwide Togolese residents and evaluated a generalized hypothetical scenario. Data from national households were obtained in person by the government between 2018 and 2019 and used for this scenario. Consumption was used as the ground truth estimate of poverty in the second scenario. The outcomes assessed for each targeting approach were social well-being, exclusion errors, and fairness measures.
Precise targeting would enhance social welfare. For the welfare outcome, the constant relative risk aversion (CRRA) utility function was used to calculate welfare aggregates. A budget was defined for equal wealth distribution among the beneficiaries that met the targeting thresholds. The budget used by the authors was similar to that of the Novissi program (US$ 4 million). The social aid to be provided may be incorrectly estimated by the targeting approaches. Hence, fairness outcomes were assessed.
The fairness of each targeting mechanism was assessed by evaluating each mechanism’s demographical parity, viz., the extent to which each mechanism over or under-targets the vulnerable groups compared to the true rate of poverty in that group. The exclusion errors were calculated by assessing the extent to which truly poor individuals were excluded from the analysis by mistake.
Results
In the first scenario, the phone-based targeting approach [area under the curve (AUC) 0.7] outperformed the other targeting approaches (geographic blanket targeting AUC 0.6). Additionally, the exclusion errors were lower in the phone-based approach (53%) than in other approaches (59%–78%).
Likewise, in the second scenario, the phone-based targeting approach (AUC 0.7) most effectively prioritized the poor compared to the other approaches, with lesser exclusion errors (50%) than the other approaches (52%–76%).
Notably, the occupation-targeting approach could not attain national-level scalability and had higher exclusion (76%) compared to the team’s optimal targeting approach with lower exclusion errors (48%). Taken together, the phone-based approach demonstrated higher efficacy in the first scenario.
Interestingly, the phone expenditure-based approach performed significantly worse (AUC 0.57 and 0.63 for the first and second scenarios, respectively) than the phone-based targeting approaches (AUC 0.70 for and 0.73 for the first and second scenarios, respectively).
To summarize, the study findings demonstrated that the phone-based targeting approach that analyzed mobile phone and satellite data by machine learning could improve humanitarian assistance targeting. However, since poverty can change over time and data may become obsolete, constantly updating the data is necessary to enable the accurate disbursement of social aid to the poorest individuals.
 Free book access improves literacy rates in high-poverty schools
Free book access improves literacy rates in high-poverty schools