In combination with the previously described navigational affordance model (NAM; Bonner and Epstein), this DNN reveals that human neural processes treat 2-dimensional (2D) image tasks as low-level visual features, and those from semantic and 3-dimensional (3D) tasks as high-, and mid-level respectively. Notably, the current study reveals that the flowchart of human navigational planning involves the initial computation of 2D (low-level tasks), followed by the parallel processing of mid-level (3D) and high-level semantic tasks. Only after these hierarchical steps are concluded do navigational affordance representations emerge.
The cognitive challenges of navigation
Navigating through a scene involves the rapid extraction of multifaceted pieces of visual information and the computation of this information into navigation routes. While representing one of the most fundamental day-to-day human neural computations, the mechanisms by which the brain characterizes visual data and the order in which data processing occurs remains hotly debated and hitherto scientifically unconfirmed.
Previous research has identified three main types of visual features typical to most navigable scenes – 2-dimensional (2D), 3-dimensional (3D), and semantic. Studies focused on neural computation have produced two (confounding) findings – 1. Navigational affordance exhibits strong associations with even low-level (2D) visual features, suggesting that multiple early affordance computations can occur in parallel, thereby influencing scene perception; and 2. Navigation, primarily through convoluted indoor scenes, represents a complex cognitive feat integrating features of different task levels (2D, 3D, and semantic) with potentially differing computation durations.
“For instance, successfully navigating the immediate environment requires localizing obstacles and finding out a way around them, which necessitates 3D scene information. Similarly, semantic scene classification may benefit route planning as navigating typical basements, balconies, and garages require different procedures.”
Recent research on object affordance suggests that these affordances are the products of expectations, making them secondary to perception. Reconciling these apparently contrasting lines of evidence would require a mechanistic understanding of the computational processes underpinning navigation and knowledge of the order in which these computations are carried out in human brains.
About the study
In the present study, researchers hypothesize that the neural representation of navigational affordances follows (lags behind) representations of other lower-order visual features (2D, 3D, and semantic). To validate this hypothesis, they used electroencephalography (EEG) recordings from healthy adult human participants in tandem with novel deep neural networks (DNNs), representational similarity analysis (RSA), and a navigational affordance model (NAM) to reveal the neural order of navigational data processing.
The study cohort comprised 16 healthy adults (female n = 7) with corrected or normal vision. Data collection included demographic, anthropometric, and medical. Visual stimuli used in the study consisted of 50 color images of a spectrum of indoor scenes. These images were consistent with those used by Bonner and Epstein for consistency with the previously described NAM used herein. Images were presented to participants individually for 200 ms with a 600-800 ms gap between trials. Participants were given 1.3 seconds to choose an optimal navigation route.
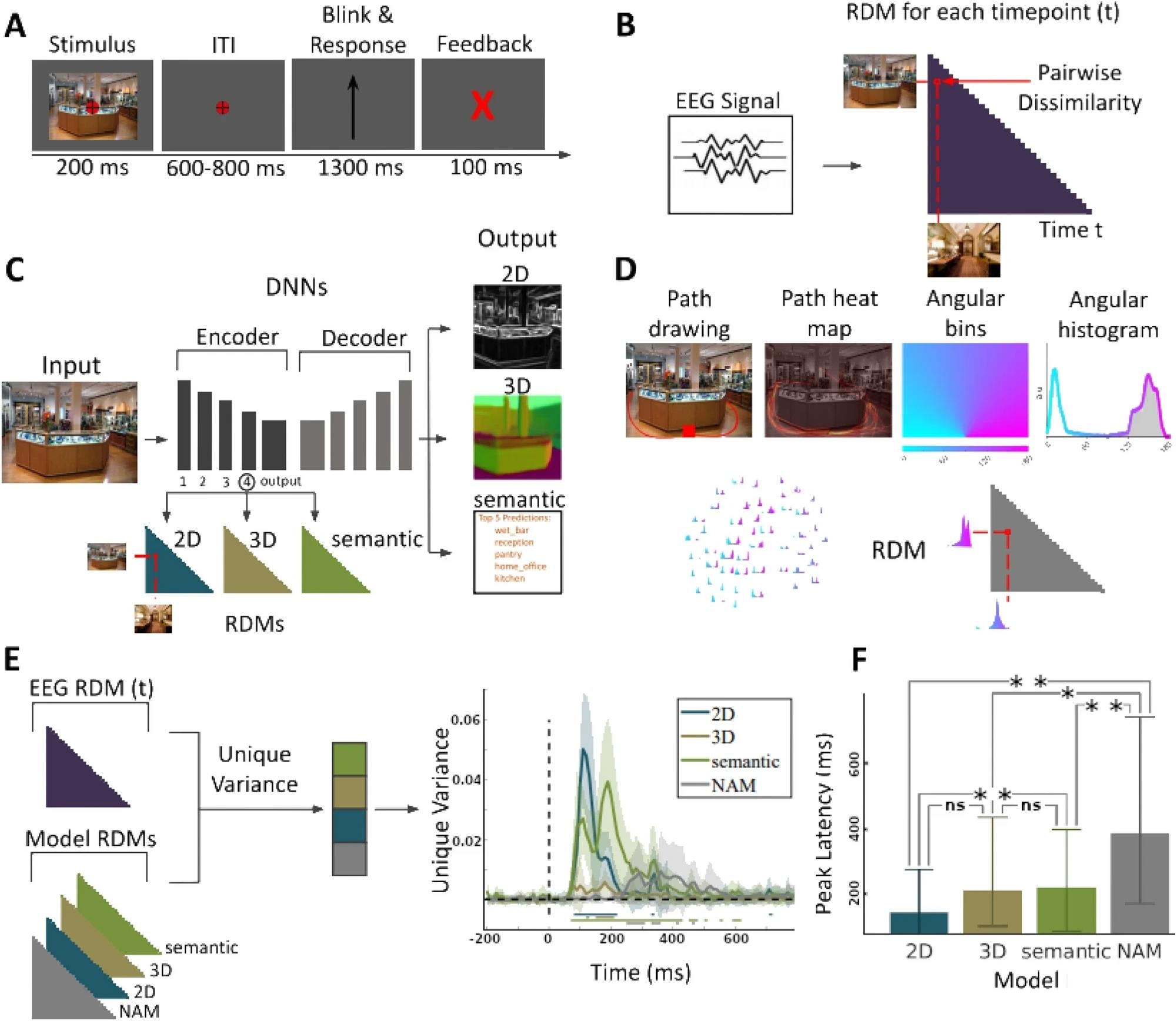 (A) EEG paradigm. Participants viewed 50 images of indoor scenes and were asked to mentally plan possible exit paths through the scenes. On interspersed catch trials participants had to respond whether the exit path displayed on the screen corresponded to any of the exit paths from the previous trial. (B) EEG RDMs. We computed RDMs for each EEG time point (every 10 ms from − 200 to + 800 ms with respect to image onset). (C) DNN RDMs. We calculated RDMs from the activations extracted from the 4th block and output layer of a ResNet50 DNN trained on 2D, 3D, and semantic tasks. (D) NAM model and RDM5. (E) Variance partitioning. We calculated the unique EEG variance explained by each of the models, revealing different temporal activation patterns. Lines below the plots indicate significant times using t-test (FDR corrected p < 0.05). (F) Peak latencies of different models. Error bars indicate the 95% confidence interval. For significance testing, we applied bootstrapping followed by FDR correction. We found no significant differences between the correlation peak latency between 2D and 3D models or 3D and semantic models. However there were significant differences between 2D and semantic models, 2D and NAM models), 3D and NAM models, and semantic and NAM models).
(A) EEG paradigm. Participants viewed 50 images of indoor scenes and were asked to mentally plan possible exit paths through the scenes. On interspersed catch trials participants had to respond whether the exit path displayed on the screen corresponded to any of the exit paths from the previous trial. (B) EEG RDMs. We computed RDMs for each EEG time point (every 10 ms from − 200 to + 800 ms with respect to image onset). (C) DNN RDMs. We calculated RDMs from the activations extracted from the 4th block and output layer of a ResNet50 DNN trained on 2D, 3D, and semantic tasks. (D) NAM model and RDM5. (E) Variance partitioning. We calculated the unique EEG variance explained by each of the models, revealing different temporal activation patterns. Lines below the plots indicate significant times using t-test (FDR corrected p < 0.05). (F) Peak latencies of different models. Error bars indicate the 95% confidence interval. For significance testing, we applied bootstrapping followed by FDR correction. We found no significant differences between the correlation peak latency between 2D and 3D models or 3D and semantic models. However there were significant differences between 2D and semantic models, 2D and NAM models), 3D and NAM models, and semantic and NAM models).
“The paradigm was designed to engage the participants in explicit navigational affordance processing of every image. While viewing the stimuli, participants were asked to imagine the directions of the navigational paths relative to the participant’s viewpoint, i.e., whether the paths were leading to the left, the center, or the right.”
Continuous participant neural activity was recorded using an Easycap 64-channel standard electrode system for EEG measurements. Bonner and Epstein’s NAM model was used without modification, followed by angular binning to generate a navigational affordance histogram. This, in turn, was combined with behavioral data to arrive at a navigational affordance representational dissimilarity matrix (RDM).
“RSA analysis with fMRI recordings revealed affordance representations in the occipital place area. We utilize the same quantification of navigational affordance (via the NAM RDM) to explore when, rather than where, affordance representations emerge.”
More than 4.5 million fully annotated indoor images from the Taskonomy Task Bank were used to train the 18 deep neural network (DNN) models. From the 18 pre-classified tasks present in the images, the DNN models arrived at three classes differing in their visual complexity levels, approximating 2D (low-level), 3D (mid-level), and semantic (high-level) tasks. Finally, representational similarity analysis (RSA) was used to compare participant responses (EEG) and DNN outputs.
Study findings and outcomes
Results from the present study reveal that, when presented with a spectrum of visual data of differing complexity, a temporal processing hierarchy is followed. Low-level 2D tasks are first processed as early as 128.12 ± 3.56 ms following stimulus exposure. Semantic and 3D data processing then occur almost in parallel at 161.87 ± 10.45 ms and 171.87 ± 30.79 ms, respectively.
Participants took, on average, 296.25 ± 37.05 ms to complete processing data and arrive at a potential optimal navigation route.
“Navigational affordance representation emerged significantly later than 2D, 3D, and semantic representations. This suggests by temporal order that humans leverage those features to process navigational affordances.”
While an immediately apparent ecological limitation of the study exists – the images used in the study were static, while in routine scenarios, humans need to dynamically update their navigational routes due to the dynamic nature of objects in their vicinity – these results provide preliminary insights into the mechanisms allowing us to seamlessly transition through the complex physical landscapes we constantly encounter in our day-to-day lives.
 Gut microbes may drive memory decline during aging by disrupting vagal brain signaling
Gut microbes may drive memory decline during aging by disrupting vagal brain signaling