In a recent study published in the International Journal for Educational Integrity, researchers in China compared, for the first time, the accuracy of artificial intelligence (AI)-based content detectors and human reviewers in detecting AI-generated rehabilitation-related articles, both original and paraphrased. They found that among the given tools, Originality.ai detected 100% of AI-generated texts, professorial reviewers accurately identified at least 96% of AI-rephrased articles, and student reviewers identified 76% of AI-rephrased articles, highlighting the effectiveness of AI detectors and experienced reviewers.
 Study: The great detectives: humans versus AI detectors in catching large language model-generated medical writing. Image Credit: ImageFlow / Shutterstock
Study: The great detectives: humans versus AI detectors in catching large language model-generated medical writing. Image Credit: ImageFlow / Shutterstock
Background
ChatGPT (short for "Chat Generative Pretrained Transformer"), a large language model (LLM) chatbot, is widely used in various fields. In medicine and digital health, this AI tool may be used to perform tasks such as generating discharge summaries, aiding diagnosis, and providing health information. Despite its utility, scientists oppose granting it authorship in academic publishing due to concerns about accountability and reliability. AI-generated content may potentially be misleading, necessitating robust detection methods. Existing AI detectors, like Turnitin and Originality.ai, show promise but struggle with paraphrased texts and often misclassify human-written articles. Human reviewers also exhibit moderate accuracy in detecting AI-generated content. Continuous efforts to improve AI detection and develop discipline-specific guidelines are crucial for maintaining academic integrity. To address this gap, researchers in the present study aimed to examine the accuracy of popular AI content detectors in identifying LLM-generated academic articles and compare them with human reviewers with varied levels of research training.
About the study
In the present study, 50 peer-reviewed papers related to rehabilitation were chosen from high-impact journals. Artificial research papers were then created using specific prompts in ChatGPT version 3.5 (asking it to mimic an academic writer). The resulting articles were rephrased using Wordtune to improve their authenticity. Further, six AI-based content detectors were used to differentiate between original, ChatGPT-generated, and AI-rephrased papers. The included tools were either free to use (GPTZero, ZeroGPT, Content at Scale, GPT-2 Output Detector) or paid (Originality.ai and Turnitin's AI writing detection). Importantly, the detectors did not analyze the methods and results sections of the papers. AI, perplexity, and plagiarized scores were determined for analysis and comparison. Statistical analysis involved the use of the Shapiro-Wilk test, Levene's test, analysis of variance, and paired t-test.
Additionally, four blinded human reviewers, including two college student reviewers and two professorial reviewers with backgrounds in physiotherapy and varying research training levels, were given the tasks of reviewing and discerning between original and AI-rephrased articles. The reviewers were also probed to understand the reasoning behind their classification of articles.
Results and discussion
The accuracy of AI content detectors in identifying AI-generated articles was found to be variable. Originality.ai showed 100% accuracy in identifying both ChatGPT-generated and AI-rephrased articles, while ZeroGPT achieved 96% accuracy in identifying ChatGPT-generated articles, with a sensitivity of 98% and specificity of 92%. Further, the GPT-2 Output Detector and Turnitin showed accuracies of 96% and 94%, respectively, for ChatGPT-generated articles, but Turnitin's accuracy reduced to 30% for AI-rephrased articles. GPTZero and Content at Scale showed lower accuracies in identifying ChatGPT-generated papers, with Content at Scale misclassifying 28% of the original articles. Interestingly, Originality.ai was the only tool that did not assign lower AI scores to rephrased articles as compared to ChatGPT-generated articles.
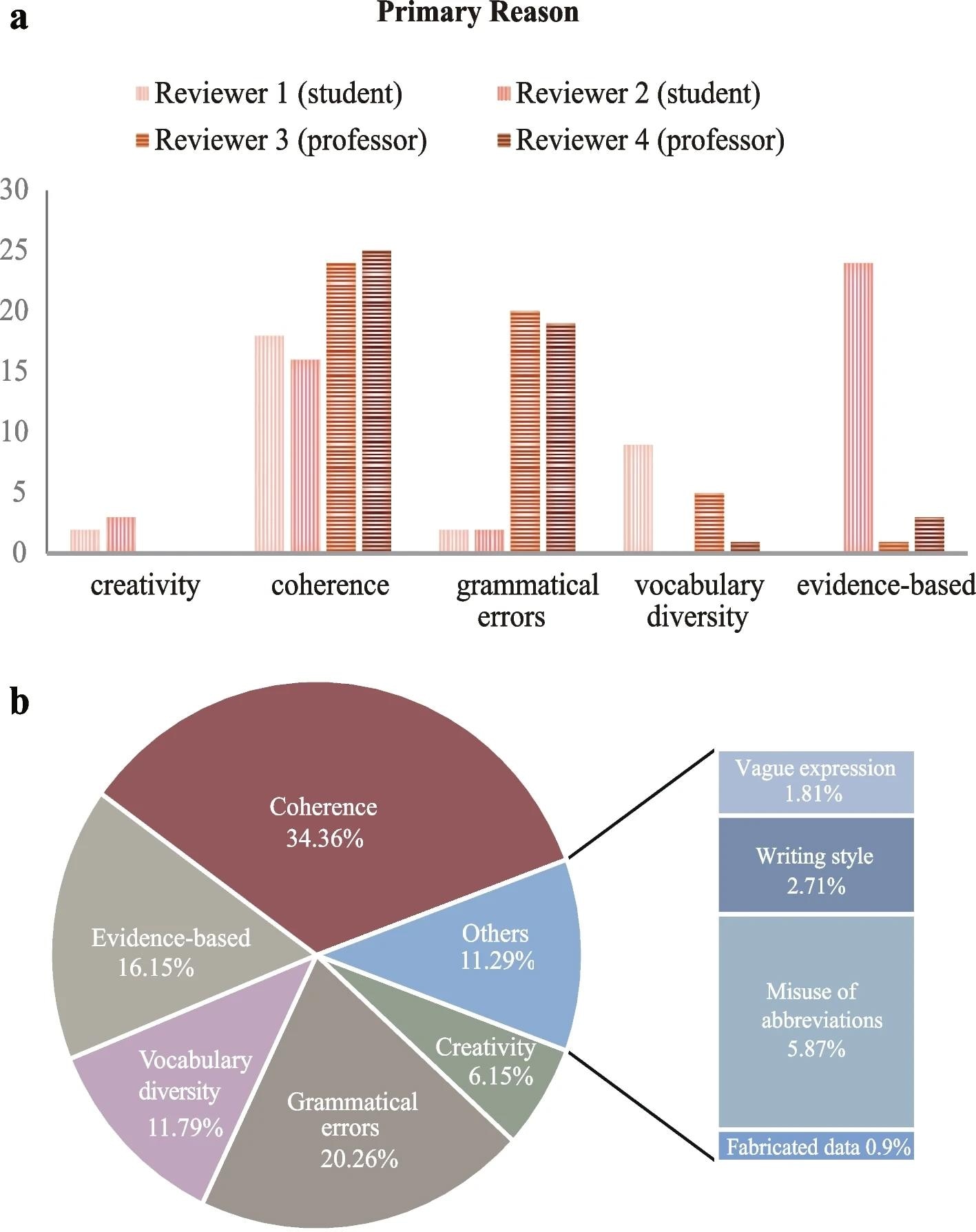 A The frequency of the primary reason for artificial intelligence (AI)-rephrased articles being identified by each reviewer. B The relative frequency of each reason for AI-rephrased articles being identified (based on the top three reasons given by the four reviewers)
A The frequency of the primary reason for artificial intelligence (AI)-rephrased articles being identified by each reviewer. B The relative frequency of each reason for AI-rephrased articles being identified (based on the top three reasons given by the four reviewers)
In the human reviewer analysis, the median time taken by the four reviewers to distinguish original from AI-rephrased articles was 5 minutes and 45 seconds. High accuracy rates of 96% and 100% were observed in the two professorial reviewers' discerning AI-rephrased articles, though they incorrectly classified 12% of human-written articles as AI-rephrased. On the other hand, student reviewers could only achieve 76% accuracy in identifying AI-rephrased articles. The primary reasons for identifying articles as AI-rephrased were found to be lack of coherence (34.36%), grammatical errors (20.26%), and insufficient evidence-based claims (16.5%), followed by vocabulary diversity, misuse of abbreviations, creativity, writing style, vague expression, and conflicting data. Inter-rater agreement was observed between professorial reviewers, demonstrating near-perfect agreement in binary responses and fair agreement in identifying primary and secondary reasons.
Furthermore, Turnitin showed significantly lower plagiarized scores for ChatGPT-generated and AI-rephrased articles compared to original ones. The scores or reviewer evaluations between original papers published before and after the launch of GPT-3.5-Turbo were not found to be significantly different.
The present study is the first to provide valuable and timely insights into the ability of newer AI detectors and human reviewers to identify AI-generated scientific text, both original and paraphrased. However, the findings are limited by the use of ChatGPT-3.5 (an older version), the potential inclusion of AI-assisted original papers, and a small number of reviewers. Further research is required to address these constraints and improve generalizability in various fields.
Conclusion
In conclusion, the study validates the peer-reviewed system's effectiveness in reducing the risk of publishing AI-generated medical content, proposing Originality.ai and ZeroGPT as useful initial screening tools. It highlights ChatGPT's limitations and calls for ongoing improvement in AI detection, emphasizing the need to regulate AI usage in medical writing to maintain scientific integrity.
 Measuring AI acceptance among Japanese medical students and rresident physicians
Measuring AI acceptance among Japanese medical students and rresident physicians