In a recent study published in the journal PLOS Digital Health, researchers assessed and compared the clinical knowledge and diagnostic reasoning capabilities of large language models (LLMs) with those of human experts in the field of ophthalmology.
 Study: Large language models approach expert-level clinical knowledge and reasoning in ophthalmology: A head-to-head cross-sectional study. Image Credit: ozrimoz / Shutterstock
Study: Large language models approach expert-level clinical knowledge and reasoning in ophthalmology: A head-to-head cross-sectional study. Image Credit: ozrimoz / Shutterstock
Background
Generative Pre-trained Transformers (GPTs), GPT-3.5 and GPT-4, are advanced language models trained on vast internet-based datasets. They power ChatGPT, a conversational artificial intelligence (AI) notable for its medical application success. Despite earlier models struggling in specialized medical tests, GPT-4 shows significant advancements. Concerns persist about data 'contamination' and the clinical relevance of test scores. Further research is needed to validate language models' clinical applicability and safety in real-world medical settings and address existing limitations in their specialized knowledge and reasoning capabilities.
About the study
Questions for the Fellowship of the Royal College of Ophthalmologists (FRCOphth) Part 2 examination were extracted from a specialized textbook that is not widely available online, minimizing the likelihood of these questions appearing in the training data of LLMs. A total of 360 multiple-choice questions spanning six chapters were extracted, and a set of 90 questions was isolated for a mock examination used to compare the performance of LLMs and doctors. Two researchers aligned these questions with the categories specified by the Royal College of Ophthalmologists, and they classified each question according to Bloom's taxonomy levels of cognitive processes. Questions with non-text elements that were unsuitable for LLM input were excluded.
The examination questions were input into versions of ChatGPT (GPT-3.5 and GPT-4) to collect responses, repeating the process up to three times per question where necessary. Once other models like Bard and HuggingChat became available, similar testing was conducted. The correct answers, as defined by the textbook, were noted for comparison.
Five expert ophthalmologists, three ophthalmology trainees, and two generalist junior doctors independently completed the mock examination to evaluate the models' practical applicability. Their answers were then compared against the LLMs' responses. Post-exam, these ophthalmologists assessed the LLMs' answers using a Likert scale to rate accuracy and relevance, blind to which model provided which answer.
This study's statistical design was robust enough to detect significant performance differences between LLMs and human doctors, aiming to test the null hypothesis that both would perform similarly. Various statistical tests, including chi-squared and paired t-tests, were applied to compare performance and assess the consistency and reliability of LLM responses against human answers.
Study results
Out of 360 questions contained in the textbook for the FRCOphth Part 2 examination, 347 were selected for use, including 87 from the mock examination chapter. The exclusions primarily involved questions with images or tables, which were unsuitable for input into LLM interfaces.
Performance comparisons revealed that GPT-4 significantly outperformed GPT-3.5, with a correct answer rate of 61.7% compared to 48.41%. This advancement in GPT-4's capabilities was consistent across different types of questions and subjects, as outlined by the Royal College of Ophthalmologists. Detailed results and statistical analyses further confirmed the robust performance of GPT-4, making it a competitive tool even among other LLMs and human doctors, particularly junior doctors and trainees.
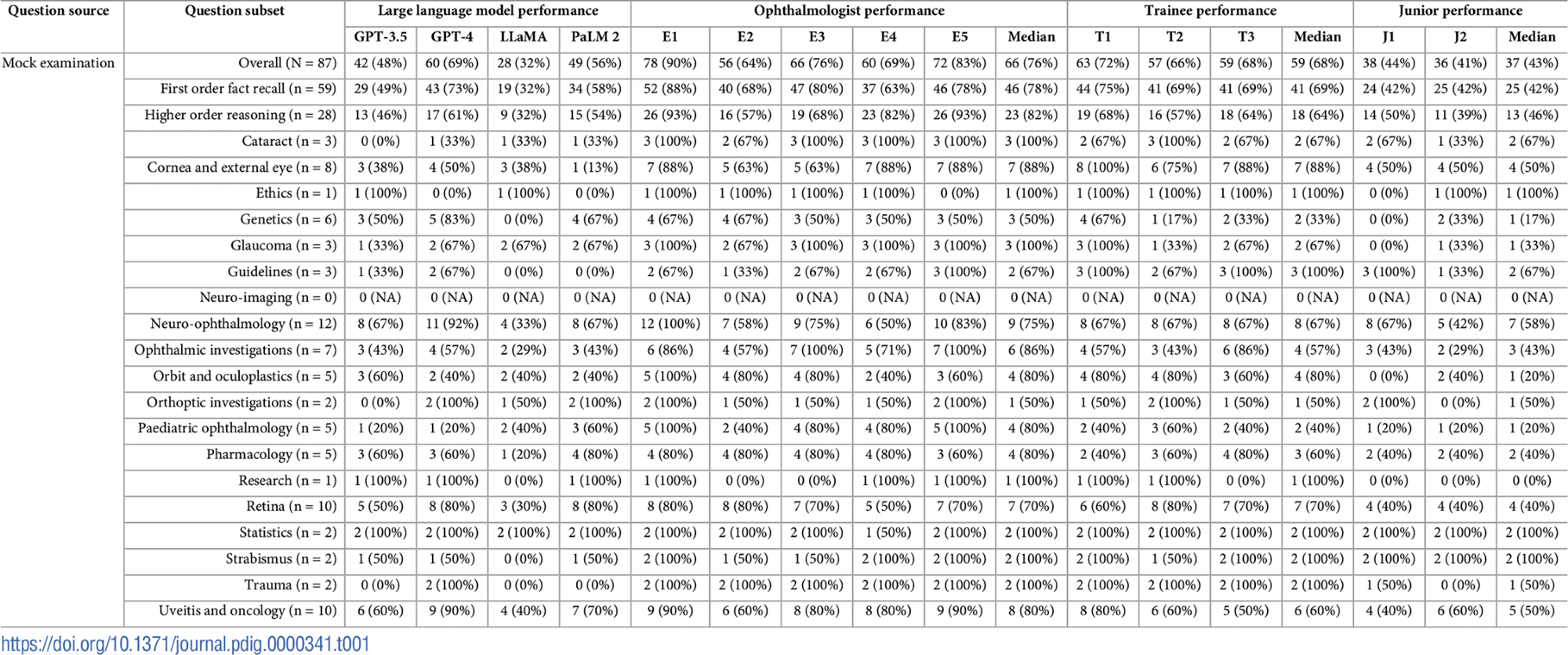 Examination characteristics and granular performance data. Question subject and type distributions presented alongside scores attained by LLMs (GPT-3.5, GPT-4, LLaMA, and PaLM 2), expert ophthalmologists (E1-E5), ophthalmology trainees (T1-T3), and unspecialised junior doctors (J1-J2). Median scores do not necessarily sum to the overall median score, as fractional scores are impossible.
Examination characteristics and granular performance data. Question subject and type distributions presented alongside scores attained by LLMs (GPT-3.5, GPT-4, LLaMA, and PaLM 2), expert ophthalmologists (E1-E5), ophthalmology trainees (T1-T3), and unspecialised junior doctors (J1-J2). Median scores do not necessarily sum to the overall median score, as fractional scores are impossible.
In the specifically tailored 87-question mock examination, GPT-4 not only led among the LLMs but also scored comparably to expert ophthalmologists and significantly better than junior and trainee doctors. The performance across different participant groups illustrated that while the expert ophthalmologists maintained the highest accuracy, the trainees approached these levels, far outpacing the junior doctors not specialized in ophthalmology.
Statistical tests also highlighted that the agreement between the answers provided by different LLMs and human participants was generally low to moderate, indicating variability in reasoning and knowledge application among the groups. This was particularly evident when comparing the differences in knowledge between the models and human doctors.
A detailed examination of the mock questions against real examination standards indicated that the mock setup closely mirrored the actual FRCOphth Part 2 Written Examination in difficulty and structure, as agreed upon by the ophthalmologists involved. This alignment ensured that the evaluation of LLMs and human responses was grounded in a realistic and clinically relevant context.
Moreover, the qualitative feedback from the ophthalmologists confirmed a strong preference for GPT-4 over GPT-3.5, correlating with the quantitative performance data. The higher accuracy and relevance ratings for GPT-4 underscored its potential utility in clinical settings, particularly in ophthalmology.
Lastly, an analysis of the instances where all LLMs failed to provide the correct answer did not show any consistent patterns related to the complexity or subject matter of the questions.
 AI-powered digital twin of mouse visual cortex
AI-powered digital twin of mouse visual cortex